
用Python抓贝壳找房的租房信息,具体要怎么写代码实现?
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考
Python内容推荐

Python-链家网和贝壳网房价爬虫
链家网和贝壳网房价爬虫,采集北京上海广州深圳等21个中国主要城市的房价数据(小区,二手房,出租房,新房),稳定可靠快速!支持csv,MySQL, MongoDB,Excel, json存储,支持Python2和3,图表展示数据,注释丰富

python开发的成都租房信息系统.zip
python开发的成都租房信息系统.zip
Python爬虫房价可视化[可运行源码]
该项目是一个基于Python的爬虫工具,用于从多个租房网站(如贝壳找房、链家网和58同城)抓取租房信息,并进行数据存储与可视化分析。项目支持自定义城市和爬取页数,自动将数据保存为CSV格式,并提供价格、户型、面积等关键信息的提取功能。同时,通过Pandas、Matplotlib和Seaborn等库实现数据的统计分析和可视化展示。代码中包含详细的解析逻辑和延时设置,以避免被目标网站封禁IP。该项目旨在帮助用户了解租房市场趋势,适用于学习交流用途,但不建议用于非法活动。
计算机中的Python爬虫及其可视化
Python爬虫项目:多平台租房数据采集与可视化分析 这是一个用于爬取链家网、贝壳找房和58同城租房信息的Python项目,提供数据采集、分析及可视化功能。项目支持爬取指定城市的房源信息,包括标题、位置、户型、面积和价格等数据,并自动保存为CSV格式。主要特点包括: 多平台支持:可同时采集链家、贝壳、58同城数据 参数可配置:自定义爬取页数、目标城市 数据处理:数据清洗、合并与分析 可视化支持:Matplotlib、Seaborn等生成图表。
基于Python的链家网贝壳网全国21城房价数据爬虫项目源码
基于Python的链家网贝壳网全国21城房价数据爬虫项目源码,支持北京上海广州深圳等国内21个主要城市;支持Python2和Python3; 基于页面的数据爬取,稳定可靠; 丰富的代码注释,帮助理解代码并且方便扩展功能。数据含义:城市-city, 区县-district, 板块-area, 小区-xiaoqu, 二手房-ershou, 租房-zufang, 新房-loupan。每个版块存储为一个csv文件,该文件可以作为原始数据进行进一步的处理和分析。 基于Python的链家网贝壳网全国21城房价数据爬虫项目源码基于Python的链家网贝壳网全国21城房价数据爬虫项目源码基于Python的链家网贝壳网全国21城房价数据爬虫项目源码基于Python的链家网贝壳网全国21城房价数据爬虫项目源码基于Python的链家网贝壳网全国21城房价数据爬虫项目源码基于Python的链家网贝壳网全国21城房价数据爬虫项目源码基于Python的链家网贝壳网全国21城房价数据爬虫项目源码基于Python的链家网贝壳网全国21城房价数据爬虫项目源码基于Python的链家网贝壳网全国21城房价数据爬虫项目源码基于Python的链家网贝壳网全国21城房价数据爬虫项目源码基于Python的链家网贝壳网全国21城房价数据爬虫项目源码基于Python的链家网贝壳网全国21城房价数据爬虫项目源码基于Python的链家网贝壳网全国21城房价数据爬虫项目源码基于Python的链家网贝壳网全国21城房价数据爬虫项目源码基于Python的链家网贝壳网全国21城房价数据爬虫项目源码基于Python的链家网贝壳网全国21城房价数据爬虫项目源码基于Python的链家网贝壳网全国21城房价数据爬虫项目源码基于Python的链家网贝壳网全国21城房价数据爬虫项目源码基于Python的链家网贝壳网全国21城房价数据爬虫项目源码
基于Python的链家网贝壳网全国21城房价数据爬虫设计源码
该项目是一款基于Python的链家网与贝壳网房价数据爬虫设计源码,包含39个文件,涵盖33个Python脚本、2个数据可视化PNG图片、1个Git忽略文件、1个Markdown文档、1个文本文件和1个SQL文件。该爬虫能够稳定高效地采集北京、上海、广州、深圳等21个中国主要城市的二手房、出租房和新房房价数据,支持CSV、MySQL、MongoDB、Excel、JSON等多种数据存储格式,兼容Python 2和3版本,并提供数据图表展示。代码注释详尽,便于理解和维护。

基于大数据的租房信息推荐系统.pdf
基于大数据的租房信息推荐系统.pdf 基于大数据的租房信息推荐系统.pdf 基于大数据的租房信息推荐系统.pdf 基于大数据的租房信息推荐系统.pdf 基于大数据的租房信息推荐系统.pdf 基于大数据的租房信息推荐系统.pdf 基于大数据的租房信息推荐系统.pdf 基于大数据的租房信息推荐系统.pdf 基于大数据的租房信息推荐系统.pdf 基于大数据的租房信息推荐系统.pdf 基于大数据的租房信息推荐系统.pdf 基于大数据的租房信息推荐系统.pdf 基于大数据的租房信息推荐系统.pdf 基于大数据的租房信息推荐系统.pdf 基于大数据的租房信息推荐系统.pdf 基于大数据的租房信息推荐系统.pdf 基于大数据的租房信息推荐系统.pdf 基于大数据的租房信息推荐系统.pdf 基于大数据的租房信息推荐系统.pdf 基于大数据的租房信息推荐系统.pdf 基于大数据的租房信息推荐系统.pdf 基于大数据的租房信息推荐系统.pdf 基于大数据的租房信息推荐系统.pdf 基于大数据的租房信息推荐系统.pdf 基于大数据的租房信息推荐系统.pdf 基于大数据的租房信息推荐系统.pdf
爬取贝壳小区房产信息源码
利用python爬取贝壳小区房产数据,稍微改一下,也可以爬取二手房,新房等信息
贝壳网租房数据全量爬取与导出工具_一行代码实现指定筛选条件下北京东城整租等全量房源信息的自动化采集与存储_通过简洁API接口快速获取贝壳网租房列表详情并支持JSON与CSV格式导出.zip
贝壳网租房数据全量爬取与导出工具_一行代码实现指定筛选条件下北京东城整租等全量房源信息的自动化采集与存储_通过简洁API接口快速获取贝壳网租房列表详情并支持JSON与CSV格式导出.zip
贝壳二手房全国房产信息爬虫存入mysql.zip
贝壳二手房全国房产信息爬虫存入mysql
爬取北,上,广租房信息.zip
租房是指通过支付一定的租金,在出租方的房屋中获得居住权的行为
scrapy爬虫之贝壳房产.zip
scrapy+mysql+html+pyecharts 数据爬取和数据分析和最终网页呈现

Hadoop之租房数据分析系统
技术路线: 1、数据爬取:基于python爬取贝壳网站的租房信息,并进行数据清洗 2、数据分析:基于MapReduce计算框架进行数据分析,分析维度包括:租房类型分析、各小区租房数量分析、各小区租房均价、租房价格范围分析、居室类型分析等 3、数据可视化:Python+Flask+echarts+MySQL可视化
基于Scrapy框架开发的贝壳网房产大数据爬虫系统_专注于爬取全国各城市小区信息二手房数据新楼盘价格租房市场行情_实现高效采集存储分析中国房地产市场的实时交易数据价格趋势区域分布_.zip
基于Scrapy框架开发的贝壳网房产大数据爬虫系统_专注于爬取全国各城市小区信息二手房数据新楼盘价格租房市场行情_实现高效采集存储分析中国房地产市场的实时交易数据价格趋势区域分布_.zip
基于Scrapy框架的南昌市租房信息爬虫系统源码
该项目为基于Scrapy框架的南昌市租房信息爬虫系统源码,总计包含89个文件,涵盖26个Python脚本、18个字节码文件、17个HTML文件、9个PNG图像文件、6个JavaScript文件、3个Markdown文件、3个CSS样式文件、2个JPG图像文件、1个Git忽略规则文件以及1个地图文件。该系统专注于抓取并整合南昌市贝壳网、安居客、链家网和58同城等平台的租房房源信息,并支持设置个性化需求后通过邮件推送定制化房源信息。
链家网和贝壳网房价爬虫,采集北京上海广州深圳等21个中国主要城市的房价数据(小区,二手房,出租房,新房),稳定可靠快速!支持csv,MySQL, MongoDB,Excel, json存储,支持Pyt
资源下载链接为: https://pan.quark.cn/s/7fe31ed2d898 链家网和贝壳网房价爬虫,采集北京上海广州深圳等21个中国主要城市的房价数据(小区,二手房,出租房,新房),稳定可靠快速!支持csv,MySQL, MongoDB,Excel, json存储,支持Python2和3,图表展示数据,注释丰富 ,点星支持,仅供学习参考,请勿用于商…(最新、最全版本!打开链接下载即可用!)
安居客出租房(武汉为例)爬虫+数据分析+可视化
### 安居客出租房(武汉为例)爬虫+数据分析+可视化 这个爬虫是我前段时间在淘宝上做单子的时候遇见的一个客户需求。本来以为就是一个简单的爬虫项目。但后面客户加了数据清洗和数据分析的要求。而后又加了要详细代码解释的需求等等。直到最后客户坦白说这是他们大专的毕设.......但是这个单子坐下来只有200左右,我想了一下,感觉好亏啊。在淘宝上随便找一个做毕设的都要好多钱的,而且客户本身的代码能力、数学、逻辑能力都很差,导致我每行都给注释以及看不懂,在我交付代码后又纠缠了我一个多礼拜。反正总体做下来的感觉就是烦躁。头一次感觉到了客户需求变更带来的巨大麻烦。 总之这是一次不是很愉快的爬虫经历。但是作为我写爬虫以来注释最详细的一次,以及第一次真正使用像matplotlib这种数据分析库的代码,我认为还是有必要分享出来给大家当个参考的(PS:大佬轻拍~)。爬虫本身几乎没有什么难度,写的也比较乱,敬请见谅。 **功能** 爬取安居客上的出租房信息(武汉地区的),并通过爬取的数据进行数据清洗以及数据分析。给出四个不同层面的可视化图。最终结果如下图所示: 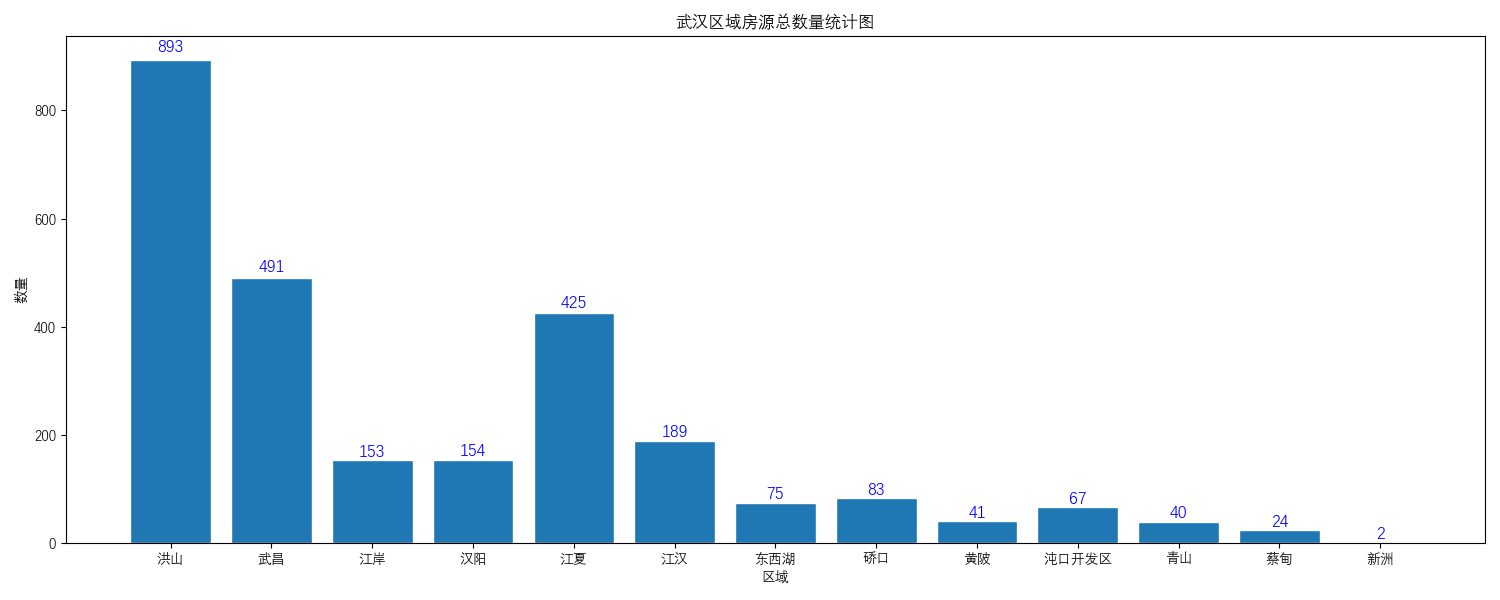 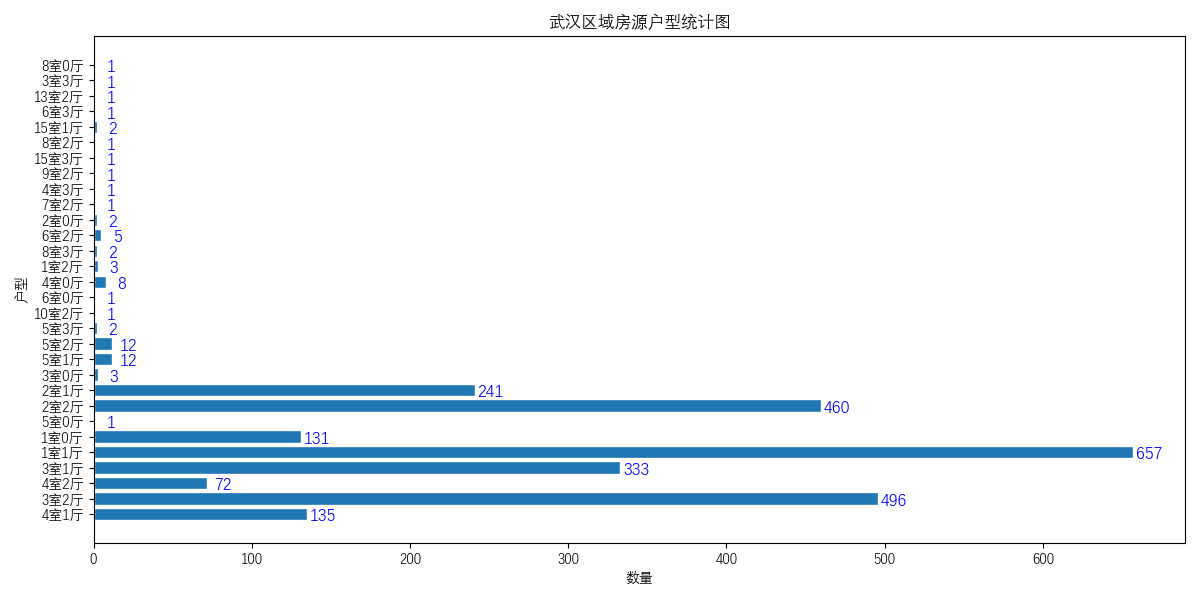 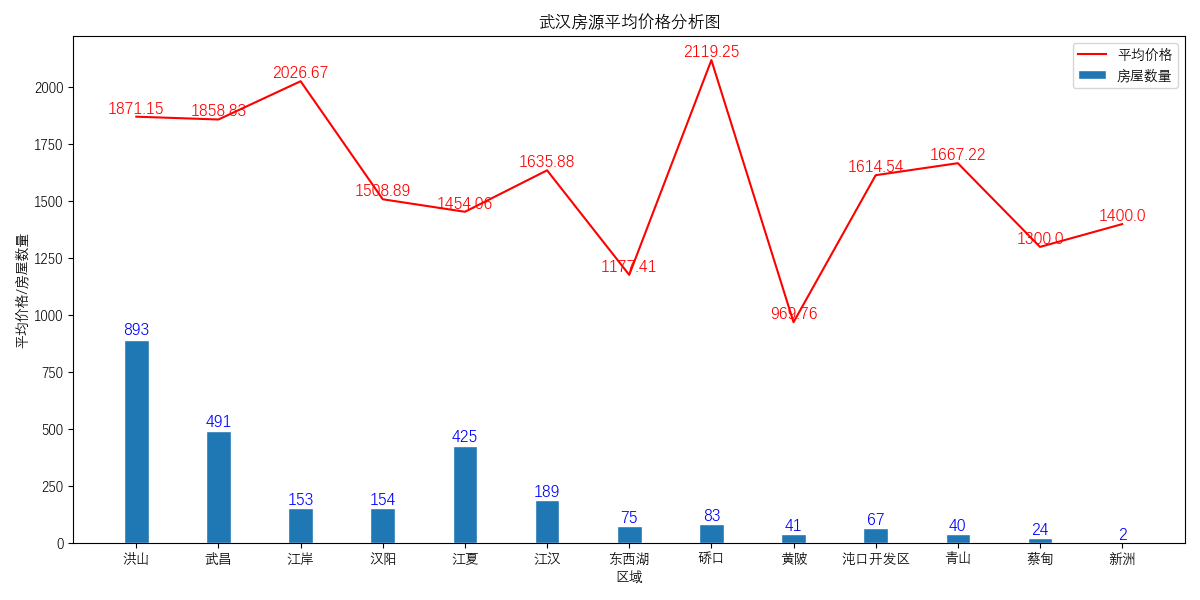  **环境** 1. Windows 10 2. python3.7 **使用方法** 首先声明该爬虫由于是特定情况下写的,所以本身的通用性特别差,仅可以对安居客网站上的武汉的出租房信息进行爬取,且需要自己手动更新cookie。同时在对数据进行分析及可视化的时候由于也是特别针对武汉出租房的进行的,所以针对性也比较强。如果别的需求需要自己进行更改。 1. 访问[安居客网址](https://wuhan.anjuke.com/),获取cookie。 > tip:获取cookie的方法可根据[此链接](https://jingyan.baidu.com/article/5d368d1ea6c6e33f60c057ef.html) 2. 在项目中找到`spider.py`的文件,将第12行的cookie换成你自己的cookie。 3. 运行`spider.py`,获取房源信息。运行后应会产生一个`武汉出租房源情况.csv`的文件。此文件为我们从安居客上爬取的房源信息,其中包含`房屋租住链接、房屋描述、房屋地址、房屋详情(户型)以及经纪人、房屋价格`五个属性。 4. 在获取了数据之后我们运行`matplotlib.py`文件。进行数据清洗,分析,可视化。运行后即可获得**功能**中展示四个图片。 **技术栈** 1. request 2. parsel 3. pandas 4. matplotlib **进步(相比之前)** 此次爬虫相比之前的技术上可以说有减无增。但其中注释相当详细,可谓是每行代码都有注释。所以对于初学者应该有一些用处。同时使用matplotlib进行了数据分析可视化等。对于数据处理的代码的注释也是几乎每行都有注释的。
链家与贝壳多城市房价数据采集工具包(含小区/二手房/租房/新房)
一套开箱即用的Python房价数据采集工具,覆盖北京、上海、广州、深圳等21个重点城市,支持链家网和贝壳网双平台数据抓取。能自动获取小区基础信息、二手房挂牌详情、出租房源列表及新房项目动态,输出结构化数据。内置多种存储适配器,可直接导出为CSV、Excel、JSON格式,或写入MySQL、MongoDB数据库。提供多线程与协程两种并发方案(ershou_image_with_threads.py / ershou_image_with_coroutine.py),兼顾效率与稳定性;配套清洗脚本(clean.py)、可视化图表生成(xiaoqu_to_chart.py)和SQL建表语句(lianjia_xiaoqu.sql)。代码注释完整,兼容Python 2与3,含详细README说明和测试用例(test目录),适合快速部署到本地环境或服务器进行周期性数据更新。所有模块按功能分层组织:spider负责请求调度,item定义数据结构,utility封装通用方法,request处理HTTP交互,const维护常量配置,tool提供辅助函数。
链家与贝壳房价数据抓取
采集北京、上海、广州、深圳等21个中国主要城市的房价数据(小区、二手房、出租房、新房),稳定可靠快速。支持csv、MySQL、MongoDB、Excel、json存储,支持Python2和3,图表展示数据,注释丰富。爬虫是一种自动化程序,用于从互联网上收集信息,主要功能是访问网页、提取数据并存储,以便后续分析或展示。爬虫的工作流程包括URL收集、请求网页、解析内容、数据存储和遵守规则。爬虫在各个领域都有广泛应用,包括搜索引擎索引、数据挖掘、价格监测、新闻聚合等。使用爬虫需遵守法律和伦理规范,尊重网站使用政策,并确保对被访问网站的服务器负责。内容来源于网络分享,如有侵权请联系我删除。
链家网和贝壳网房价爬虫.zip
采集北京上海广州深圳等21个中国主要城市的房价数据(小区,二手房,出租房,新房),稳定可靠快速!支持csv,MySQL, MongoDB,Excel, json存储,支持Python2和3,图表展示数据,注释丰富。 爬虫(Web Crawler)是一种自动化程序,用于从互联网上收集信息。其主要功能是访问网页、提取数据并存储,以便后续分析或展示。爬虫通常由搜索引擎、数据挖掘工具、监测系统等应用于网络数据抓取的场景,仅用于学习用途。 爬虫的工作流程包括以下几个关键步骤: URL收集: 爬虫从一个或多个初始URL开始,递归或迭代地发现新的URL,构建一个URL队列。这些URL可以通过链接分析、站点地图、搜索引擎等方式获取。 请求网页: 爬虫使用HTTP或其他协议向目标URL发起请求,获取网页的HTML内容。这通常通过HTTP请求库实现,如Python中的Requests库。 解析内容: 爬虫对获取的HTML进行解析,提取有用的信息。常用的解析工具有正则表达式、XPath、Beautiful Soup等。这些工具帮助爬虫定位和提取目标数据,如文本、图片、链接等。 数据存储: 爬虫将提取的数据存储到数据库、文件或其他存储介质中,以备后续分析或展示。常用的存储形式包括关系型数据库、NoSQL数据库、JSON文件等。 遵守规则: 为避免对网站造成过大负担或触发反爬虫机制,爬虫需要遵守网站的robots.txt协议,限制访问频率和深度,并模拟人类访问行为,如设置User-Agent。 反爬虫应对: 由于爬虫的存在,一些网站采取了反爬虫措施,如验证码、IP封锁等。爬虫工程师需要设计相应的策略来应对这些挑战。 爬虫在各个领域都有广泛的应用,包括搜索引擎索引、数据挖掘、价格监测、新闻聚合等。然而,使用爬虫需要遵守法律和伦理规范,尊重网站的使用政策,并确保对被访问网站的服务器负责。
 热门内容
热门内容
 最新推荐
最新推荐